Glossary¶
Information Theory Basics¶
This glossary is mainly based on MacKay’s Information Theory, Inference and Learning Algorithms. If not marked otherwise, all information below can be found there.
Prerequisites: random variable, probability distribution
A major part of information theory is persuing answers to problems like “how to measure information content”, “how to compress data” and “how to communicate perfectly over imperfect communcation channels”.
At first we will introduce some basic definitions.
The Shannon Information Content¶
The Shannon information content of an outcome \({x}\) is defined as
The unit of this measurement is called “bits”, which does not allude to 0s and 1s.
Ensemble¶
We extend the notion of a random variable to the notion of an ensemble. An ensemble \({X}\) is a triplet \((x, A_X, P_X)\), where \(x\) is just the variable denoting an outcome of the random variable, \(A_X\) is the set of all possible outcomes and \(P_X\) is the defining probability distribution.
Entropy¶
Let \(X\) be a random variable and \(A_X\) the set of possible outcomes. The entropy is defined as
The entropy describes how much we know about the outcome before the experiment. This means
The entropy is bounded from above and below: \(0 \leq H(X) \leq log_2(|A_X|)\). Notice that entropy is defined as the average Shannon information content of an outcome and therefore is also measured in bits.
Entropy for two dependent variables¶
Let \(X\) and \(Y\) be two dependent random variables.
joint entropy
conditional entropy if one variable is observed
conditional entropy in general
chain rule for entropy
Mutual Information¶
Let \(X\) and \(Y\) be two random variables. The mutual information between these variables is then defined as
The mutual information describes how much uncertainty about the one variable remains if we observe the other. It holds that
The following figure gives a good overview:
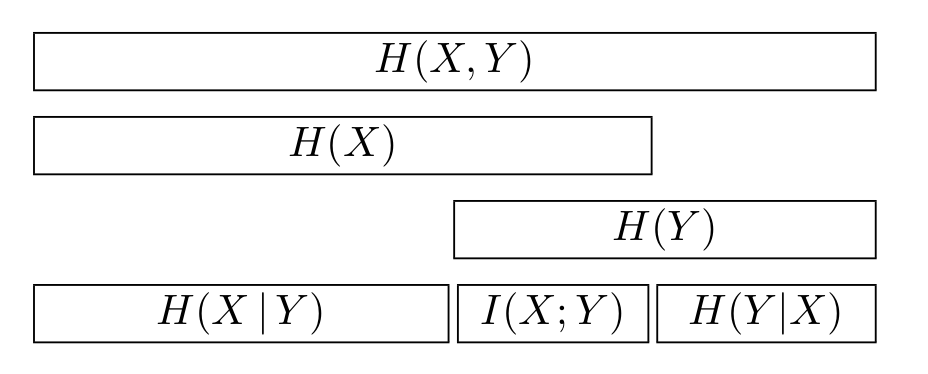
Mutual information overview.
Kullback-Leibler divergence¶
Let \(X\) be a random variable and \(p(x)\) and \(q(x)\) two probability distributions over this random variable. The Kullback-Leibler divergence is defined as
The Kullback-Leibler divergence is often called relative entropy and denotes “something” like a distance between two distributions:
Yet it is not a real distance as symmetry is not given.
Typicality¶
We introduce the “Asymptotic equipartion” principle which can be seen as a law of large numbers. This principle denotes that for an ensemble of \(N\) independent and identically distributed (i.i.d.) random variables \(X^N \equiv (X_1, X_2, \dots, X_N)\), with \(N\) sufficiently large, the outcome \(x = (x_1, x_2, \dots , x_N)\) is almost certain to belong to a subset of \(\mathcal{A}_X^N\) with \(2^{NH(X)}\) members, each having a probability that is ‘close to’ \(2^{-NH(X)}\).
The typical set is defined as
The parameter \(\beta\) sets how close the probability has to be to \(2^{-NH}\) in order to call an element part of the typical set, \(\mathcal{A}_X\) is the alphabet for an arbitrary ensemble \(X\).